When learning to analyze text this is a great time to be alive. The bloviator-in-chief currently occupying the Oval Office provides a cornucopia of text via Twitter to use for learning purposes. Even better for analysts, the folks over at the Trump Twitter Archive have made it very easy to grab a .csv of tweets from Trump over any time period.
There are several R packages that make working with unstructured text relatively painless. The tidytext package makes quick work of tokenizing (or splitting the words the text of tweets with just a few lines of code:

What is tokenizing? In their free book, Text Mining with R, Julia Silge and David Robinson define a token as “a meaningful unit of text, most often a word, that we are interested in using for further analysis,” and “tokenization is the process of splitting text into tokens.” And as you can see it’s really easy using tidytext.
The wordcloud2 does exactly what you’d expect and helps us create a word cloud in just one line from the frequency table we created above. Or we can use the get_sentiment function from tidytext to tag words with an emotion associated. Then we can filter for the top 50 negative words and create a word cloud:


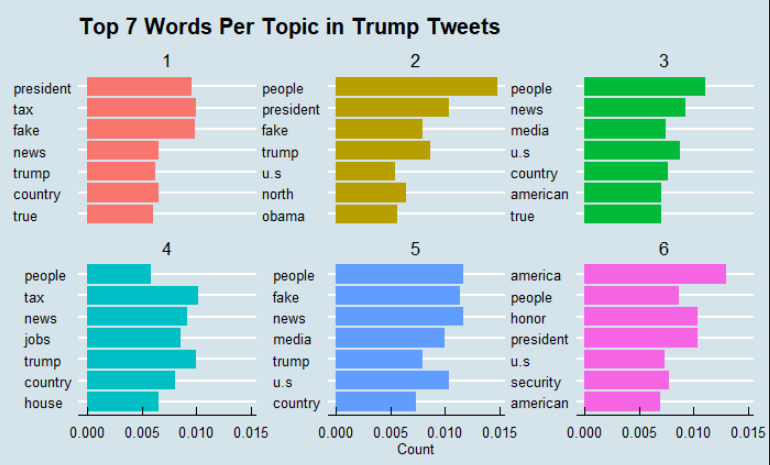
The tm package let’s us easily group words into topics by the frequency with which they occur together. (There are even more sophisticated ways of grouping words which we’ll explore another day). The table below groups the words into six topics. Looking at topics it’s clear that Trump cares a lot about the news coverage about him. Not that it wasn’t already obvious.
The openNLP package allows us to annotate the text with “entities” or people, places, organizations and dates. It’s certainly not perfect, but it doesn’t take a whole lot of code:

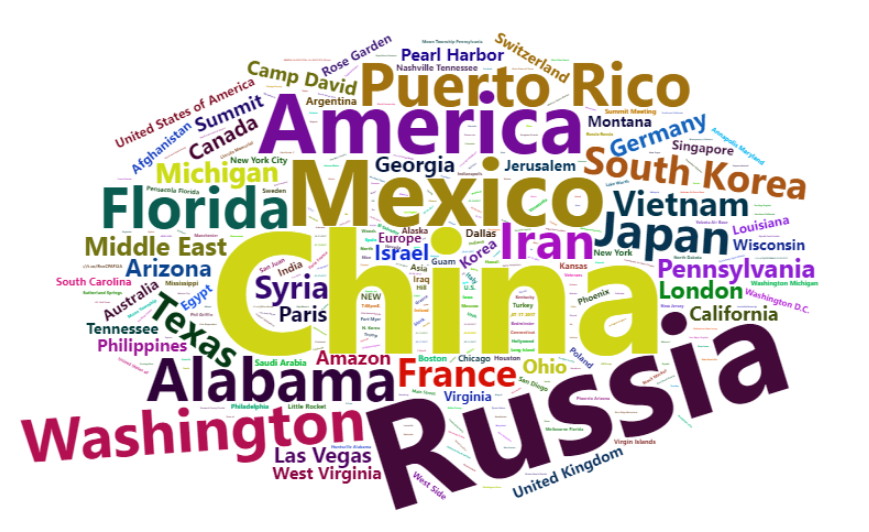
A word clouds of the locations shows Trumps favorite places to tweet about:
This just barely scratches the surface of what can be done with text analysis in R. There’s so much more that we can cover on another day.
